Cross-validation involved splitting the data into two subsets.
The two subsets are called the training data and the
validation or test data. The training data is
used to estimate the coefficients of the regression model.
The test data are used to compute the average squared
prediction error for each regression model:
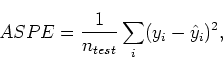
To split the data into training and test data, a random subsample of the data should be used. We did this by first generating a column of random numbers the same length as the data, sorting on the random numbers (so the data are in essentially random order), and then selecting the first 63 observations for the test data. These were cut and paste into new columns. One should select a relatively small sample for the test data so that most of the data can be used for estimating the regression coefficients. Also, one should try for at least 30 observations in the test data to provide a reasonable stable and accurate estimate of the ASPE. This is why cross validation is only reasonable for large data sets.
We ran the cross validation on all the regression models selected
by the Best Subsets method so that we could compare with ![]() .
This was done by running the Regression function on each model,
predicting at the values of the predictor variables in the test
data set, and computing the ASPE. This was admittedly rather
tedious. However, once we got started it was not too bad since
it was fairly quick to change the predictor variables in the
regression dialogue box. Also, we deleted the column of predicted
values after each run so that the next column would appear in the
same place and the ASPE calculation (done in the calc menu) never
had to be changed (simply pull down the calculator and check OK).
The value of ASPE after each run was cut and paste into a colum of
values. We also deleted most of the output from the regression
command.
.
This was done by running the Regression function on each model,
predicting at the values of the predictor variables in the test
data set, and computing the ASPE. This was admittedly rather
tedious. However, once we got started it was not too bad since
it was fairly quick to change the predictor variables in the
regression dialogue box. Also, we deleted the column of predicted
values after each run so that the next column would appear in the
same place and the ASPE calculation (done in the calc menu) never
had to be changed (simply pull down the calculator and check OK).
The value of ASPE after each run was cut and paste into a colum of
values. We also deleted most of the output from the regression
command.
The Stepwise and Best Subsets methods were run originally on the entire data set using the original origin variable. After that, a new data set was constructed by first creating the origin indicator variables and the two methods were run again. Finally, we dropped the variables cylinder (number of cylinders) and acc (acceleration) since neither Stepwise nor Best Subsets wanted them (I had to decrease the size of my data set because of the limits of the student edition of Minitab), selected the random subset of test data, and reran the two methods on the training data as well as cross validation.